Introdução à Análise de Dados em R utilizando Tidyverse
2023-10-27
Bem-vindo!
Este é o repositório do livro texto do curso de Introdução à Análise de Dados em R utilizando Tidyverse. Para reproduzir os códigos presentes no livro, você precisa de uma versão recente do R e pacotes atualizados. Ao início de cada seção, você será apresentado aos pacotes necessários para executar os códigos referentes àquele assunto.
Todos os datasets e outros arquivos de dados a serem utilizados durante os Módulos, estão disponíveis no repositório Git deste livro, na pasta datasets: https://github.com/allanvc/book_IADR-T/tree/master/datasets
Também recomenda-se a utilização da versão mais recente do Ambiente Integrado de Desenvolvimento (IDE) RStudio.
Por que R ?
A linguagem de programação R é conhecida por ter uma curva de aprendizagem relativamente lenta, mas, uma vez que o aluno entende a estrutura básica de objetos que compõe a linguagem, o aprendizado passa a ser exponencial.
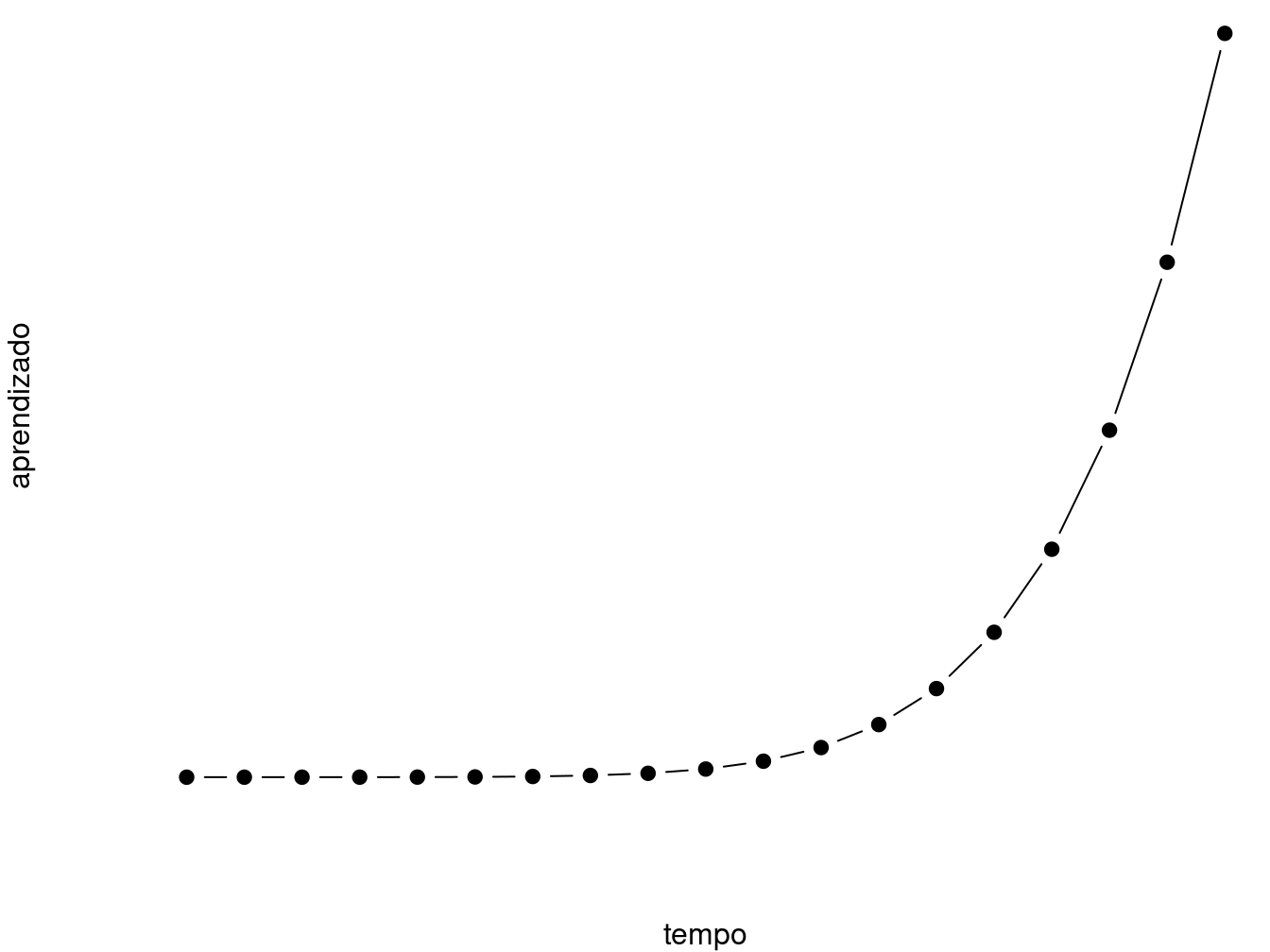
Figure 0.1: Curva de Aprendizagem R
R é relativamente diferente das demais linguagens de programação porque foi desenvolvida por Estatísticos para Estatísticos. Ela não foi pensada para ser a mais eficiente das linguagens em termos de rapidez, mas sim para tornar mais fácil a vida de quem analisa dados. Minha experiência com outras linguagens de programação levam me a afirmar que isto é verdade: não há linguagem mais adequada para realizar análise de dados do que R. Preferêncas individuais e outras conveniências podem levar a escolha de uma ou outra linguagem, mas não há como não concordar com o fato de que R possui as melhores ferramentas de Data Wrangling (preparação de dados), geração de gráficos, geração de relatórios e reproducibilidade.
Além disso, R é mundialmente reconhecido por sua comunidade extremamente ativa e inclusiva. É a linguagen preferida na academia, tendo em vista que novas técnicas matemáticas, estatísticas, e/ou computacionais são implementadas primeiro em R. É também uma das liguagens mais usadas na indústria para Ciência de Dados, juntamente com Python.
Por esses motivos e por ser uma linguagem open source, dotada de um poderoso ambiente de gerenciamento de pacotes, a disseminação do uso de R em seus 20 anos de história foi extremamente rápida e acabou por relegar ao segundo plano ambientes de análise de dados e linguagens como SAS, SPSS e Stata. No R, você encontra pacotes para as mais diversas finalidades: desde pacotes que geram provas a partir de um banco de questões, passando por pacotes de preparação de dados, otimização matemática, Machine Learning, até pacotes para análise de áudio, criação de aplicativos, leitura e envio de emails.
Hoje em dia, há diversos ambientes e linguagens utilizadas para Análise de Dados, como Python, Julia, Scala, SAS, etc. No entanto, nenhuma delas fornece a combinação de um excelente ecositema de gerenciamento de pacotes, capacidades estatísticas, opções de visualização e um poderoso IDE (Integrated Development Environment) - tudo implementado pela comunidade R. Por todas essas características, os benefícios ao aprender a linguagem R são realmente consideráveis.
Organização do Curso
Este curso é dividido em 5 Módulos. O Módulo 1 busca ambientar o aluno com os conceitos básicos da linguagem, passando pelo histórico, funcionalidades básicas e a estrutura dos objetos mais importantes no R.
Os Módulos 2 e 3 são divididos sempre em 3 partes: leitura de dados, manipulação de dados e visualização. A cada Módulo, são apresentados novos pacotes para estas funcionalidades, com um nível um pouco mais profundo de especialização em relação ao módulo anterior.
O Módulo 4 inicia-se com foco na manipulação de strings e expressões regulares (REGEX) e finaliza aprsentando técnicas de produção de relatórios e reproducibilidade no R.
Por fim, o Módulo 5 apresenta um ferramental de análise econômica regional, interessante aos Pesquisadores do IPEA, público-alvo deste curso.
Sobre o autor
Allan V. C. Quadros é autor dos pacotes R, emstreeR, mRpostman e onlineretail; e aualmente realiza o seu Ph.D. em Estatística pela Kansas State University (EUA). Sua experiência profissional inclui o cargo de Lead Data Scientist no Núcleo de Métodos Quantitativos e Assessor de Gestão Estratégica e Governança – ambos no Fundo Nacional de Desenvolvimento da Educação (FNDE); Professor Universitário; Assessor de Investimentos; e 1º Tenente de Infantaria do Exército Brasileiro. Seus principais interesses acadêmicos são Computational Statistics, Mathematical Finance, Otimização, Processos Estocásticos e Astroestatística. Ultimamente, tem atuado no desenvolvimento de pacotes R e em pesquisas acadêmicas no âmbito das disciplinas de estatística, computação e data science. Atua ainda na confecção de ferramentas de arbitragem estatística utilizadas como estratégias de investimento no mercado financeiro utilizando R e Python. Mais informações sobre o autor podem ser encontradas em: https://allanvc.github.io.
e onlineretail; e aualmente realiza o seu Ph.D. em Estatística pela Kansas State University (EUA). Sua experiência profissional inclui o cargo de Lead Data Scientist no Núcleo de Métodos Quantitativos e Assessor de Gestão Estratégica e Governança – ambos no Fundo Nacional de Desenvolvimento da Educação (FNDE); Professor Universitário; Assessor de Investimentos; e 1º Tenente de Infantaria do Exército Brasileiro. Seus principais interesses acadêmicos são Computational Statistics, Mathematical Finance, Otimização, Processos Estocásticos e Astroestatística. Ultimamente, tem atuado no desenvolvimento de pacotes R e em pesquisas acadêmicas no âmbito das disciplinas de estatística, computação e data science. Atua ainda na confecção de ferramentas de arbitragem estatística utilizadas como estratégias de investimento no mercado financeiro utilizando R e Python. Mais informações sobre o autor podem ser encontradas em: https://allanvc.github.io.